Related links
Extreme Scale computing in HPC, Big Data, Deep Learning and Clouds are marked by multiple-levels of hierarchy and heterogeneity ranging from the compute units (many-core CPUs, GPUs, APUs etc) to storage devices (NVMe, NVMe over Fabrics etc) to the network interconnects (InfiniBand, High-Speed Ethernet, Omni-Path etc). Owing to the plethora of heterogeneous communication paths with different cost models expected to be present in extreme scale systems, data movement is seen as the soul of different challenges for exascale computing. On the other hand, advances in networking technologies such as NoCs (like NVLink), RDMA enabled networks and the likes are constantly pushing the envelope of research in the field of novel communication and computing architectures for extreme scale computing. The goal of this workshop is to bring together researchers and software/hardware designers from academia, industry and national laboratories who are involved in creating network-based computing solutions for extreme scale architectures. The objectives of this workshop will be to share the experiences of the members of this community and to learn the opportunities and challenges in the design trends for exascale communication architectures.
All times in Central European Summer Time (CEST)
Workshop Program | |
2:00 - 2:05 PM |
Opening Remarks Hari Subramoni, Aamir Shafi, and Dhabaleswar K (DK) Panda, The Ohio State University |
2:05 - 2:40 PM PDF YouTube |
Keynote Speaker: Dr. Kalyan Kumaran, Argonne National Laboratory Session Chair: Dhabaleswar K (DK) Panda, The Ohio State University Title: Aurora Exascale Architecture Abstract: Aurora is an exascale supercomputer in the final stages of assembly at the Argonne Leadership Computing Facility (ALCF) in the U.S. This talk will focus on the Aurora hardware and software architectures with emphasis on the interconnect and programming models, and their impact on application performance and scalability. Speaker Bio: Dr Kalyan Kumaran is a Senior Computer Scientist and Director of Technology at the Argonne Leadership Computing Facility. He leads the Non-Recurring Engineering (NRE) collaboration with Intel to develop the hardware and software stack for Aurora, Argonne’s first exascale computer. He is an expert on performance-related activities and one of the lead architects from Argonne for their recent systems. |
2:40 - 3:00 PM PDF YouTube |
Speaker: Gilad Shainer, NVIDIA Session Chair: TBD Title: Addressing HPC/AI Performance Bottlenecks with BlueFIeld Data Processing Units Abstract: AI and scientific workloads demand ultra-fast processing of high-resolution simulations, extreme-size datasets, and highly parallelized algorithms. As these computing requirements continue to grow, the traditional GPU-CPU architecture further suffers from imbalance computing, data latency and lack of parallel or pre-data-processing. The introduction of the Data Processing Unit (DPU) brings a new tier of computing to address these bottlenecks, and to enable, for the first-time, compute overlapping and nearly zero communication latency. The session will deliver a deep dive into DPU computing, and how it can help address long lasting performance bottlenecks. Performance results of a variety of HPC and AI applications will be presented as well. Speaker Bio: Gilad Shainer serves as senior vice-president of networking at NVIDIA. Mr. Shainer serves as the chairman of the HPC-AI Advisory Council organization, the president of UCF and CCIX consortiums, a member of IBTA and a contributor to the PCISIG PCI-X and PCIe specifications. Mr. Shainer holds multiple patents in the field of high-speed networking. He is a recipient of 2015 R&D100 award for his contribution to the CORE-Direct In-Network Computing technology and the 2019 R&D100 award for his contribution to the Unified Communication X (UCX) technology. Gilad Shainer holds a MSc degree and a BSc degree in Electrical Engineering from the Technion Institute of Technology in Israel. |
3:00 - 3:20 AM PDFYouTube |
Speaker: Douglas Fuller, Cornelis Networks Session Chair: Dhabaleswar K (DK) Panda, The Ohio State University Title: Implementation and Performance Development of Omni-Path Express Abstract: Cornelis Networks released Omni-Path Express (OPX), its next-generation communication framework, in November 2022. Part of libfabric, OPX is free and open source. This presentation will outline implementation choices and methods used to improve performance on Omni-Path hardware in anticipation of Omni-Path CN5000. Speaker Bio: Douglas Fuller is vice president of software engineering at Cornelis Networks. Prior to joining Cornelis, Doug led software development teams working on cloud storage at Red Hat. His career in HPC includes experience at universities and HPC centers including Oak Ridge National Laboratory. He first installed MVAPICH 0.9 on the main compute cluster at Arizona State University. Doug holds bachelor’s and master’s degrees in computer science from Iowa State University |
3:20 - 3:40 PM |
Speaker: Pankaj Mehra, Elephance Memory Session Chair: Hari Subramoni, The Ohio State University Title: Principles for Optimizing Data Movement in Emerging Memory Hierarchies Abstract: The long anticipated split between a performance tier and a capacity tier of memory is finally upon us. By allowing memoryness to spread to increasingly disaggregated memory devices, CXL is enabling new locales for attaching and tapping into memory not only more cost-effectively but perhaps also more efficiently. The net effect on system architecture will be to deploy even more memory. In this presentation, we will extrapolate from existing far memory architectures to first define the requirements and then propose a principled architecture for working with such far memory. Speaker Bio: Pankaj Mehra is President and CEO of Elephance Memory. He actively advises Memory industry companies and volunteers as Adjunct Associate Professor of Computer Science at UC Santa Cruz. A contributor to InfiniBand 1.0 spec and an inventor of the first RDMA persistent memory devices and filesystems, Pankaj is a systems and software practitioner who conducts his research at the intersection of infrastructure and intelligence. He is a co-author/co-editor/co-inventor on 3 books, and over 100 papers and patents, and a builder of systems that have won recognition from NASA, Sandia National Labs, and Samsung Electronics, among others. He was a VP of Storage Pathfinding at Samsung, Senior Fellow and VP at SanDisk and Western Digital, WW CTO of Fusion-io, and Distinguished Technologist at HP Labs. |
3:40 - 4:00 PM YouTube |
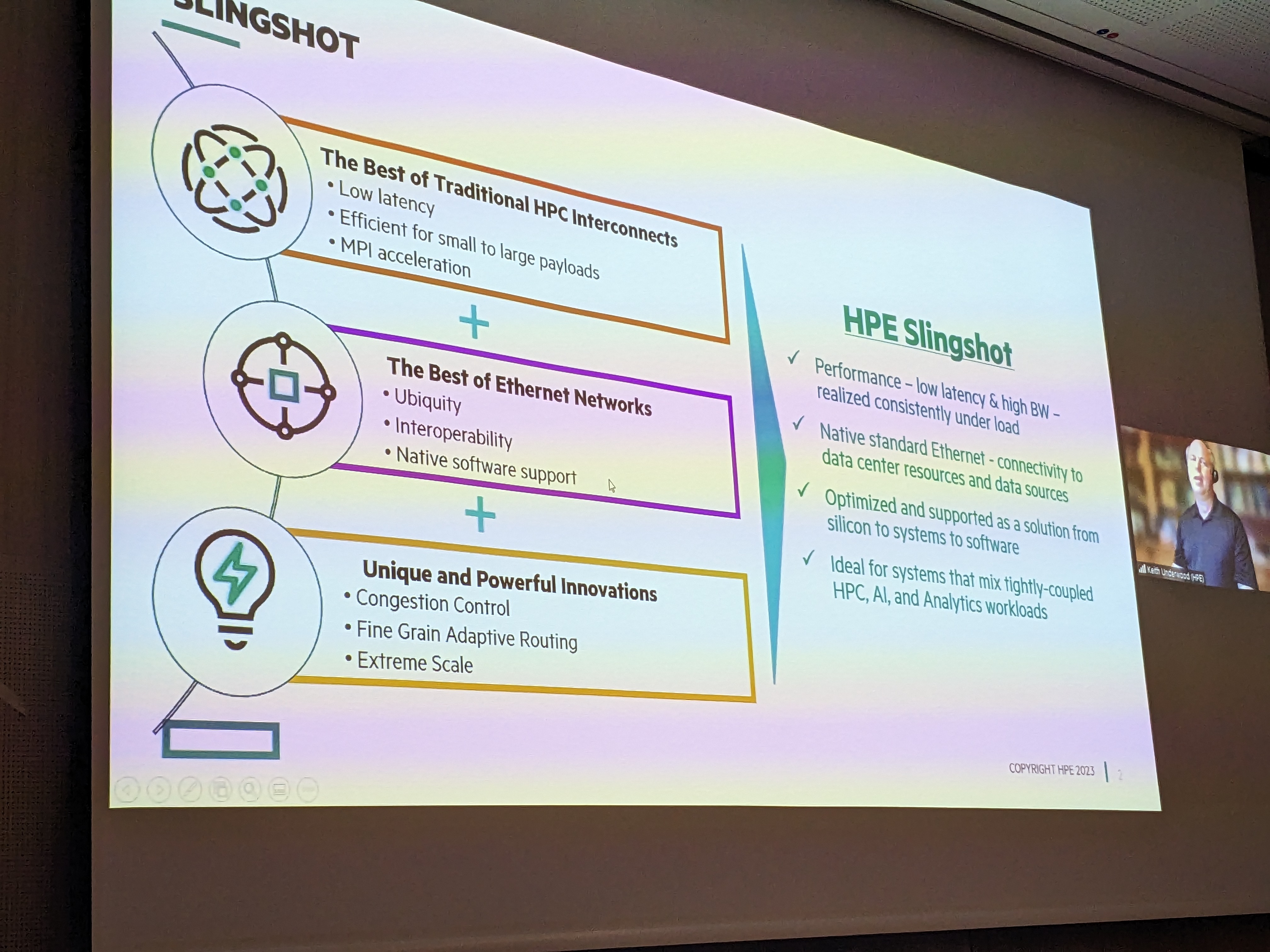
Speaker: Keith Underwood, HPE Session Chair: Hari Subramoni, The Ohio State University Title: Cassini: The Slingshot NIC Hardware and Software Enabling Exascale Abstract: Cassini and Cassini-2 are the 200 Gbps and 400 Gbps Slingshot NICs. This talk will discuss the hardware features and software functionality that enable the Cassini family of NICs to scale to tens of thousands of endpoints. Speaker Bio: Keith Underwood is a Senior Distinguished Technologist in the HPE Slingshot advanced architecture group where he leads next generation NIC architecture definition. Prior to joining Cray, Keith lead the Omni-Path 2 NIC architecture at Intel. He was part of the team that created the Portals 4 API, and the MPI-3 RMA extensions. |
4:00 - 4:30 PM |
Break |
4:30 - 4:50 PM YouTube |
Speaker: Debendra Das Sharma, Intel Session Chair: Hari Subramoni, The Ohio State University Title: Compute Express Link (CXL*): Open Load-Store Interconnect for building Composable Systems Abstract: CXL is a dynamic multi-protocol interconnect designed to support accelerators and memory devices with applications in HPC, Enterprise, and Cloud Computing segments. CXL provides a rich set of protocols that include I/O semantics like PCIe (CXL.io), caching protocol semantics (CXL.cache), and memory access semantics (CXL.mem) over PCIe PHY. The second generation of CXL, CXL 2.0, enabled dynamic resource allocation including memory and accelerator dis-aggregation across multiple servers. The third generation of CXL, CXL 3.0, doubles the bandwidth while providing larger scale composable systems with fabrics, coherent shared memory across servers, and load-store unordered I/O message passing. CXL continues its evolution while being fully backward compatible with prior generations. The availability of commercial IP blocks, Verification IPs, and industry standard internal interfaces enables CXL to be widely deployed across the industry. These along with a well-defined compliance program will ensure smooth interoperability across CXL devices in the industry. Speaker Bio: Dr. Debendra Das Sharma is an Intel Senior Fellow in the Data Platforms and Artificial Intelligence Group and chief architect of the I/O Technology and Standards Group at Intel Corporation. He drives PCI Express, Compute Express Link (CXL), Intel’s Coherency interconnect, and multichip package interconnect. He is a member of the Board of Directors of PCI-SIG and a lead contributor to PCIe specifications since its inception. He is a co-inventor and founding member of the CXL consortium and co-leads the CXL Technical Task Force. Dr. Das Sharma holds 170+ US patents and 450+ patents world-wide. He is a frequent keynote speaker, distinguished lecturer, invited speaker, and panelist at the IEEE Hot Interconnects, IEEE Cool Chips, Flash Memory Summit, PCI-SIG Developers Conference, CXL consortium events, Open Server Summit, Open Fabrics Alliance, Flash Memory Summit, SNIA SDC, and Intel Developer Forum. He has a B.Tech in Computer Science and Engineering from the Indian Institute of Technology, Kharagpur and a Ph.D. in Computer Engineering from the University of Massachusetts, Amherst. He has been awarded the Distinguished Alumnus Award from Indian Institute of Technology, Kharagpur in 2019, the IEEE Region 6 Outstanding Engineer Award in 2021, the first PCI-SIG Lifetime Contribution Award in 2022, and the IEEE Circuits and Systems Industrial Pioneer Award in 2022. |
4:50 - 5:10 PM PDFYouTube |
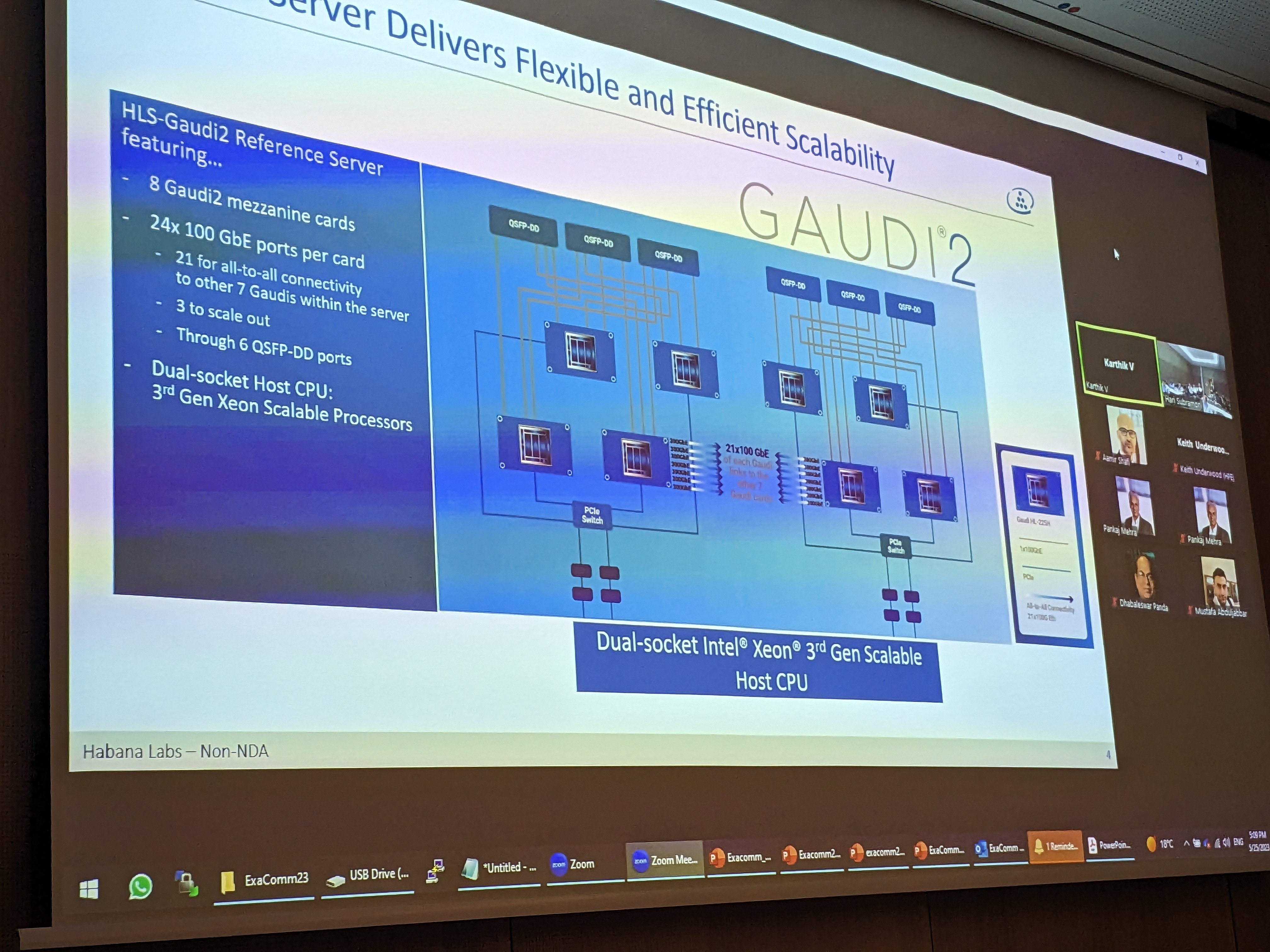
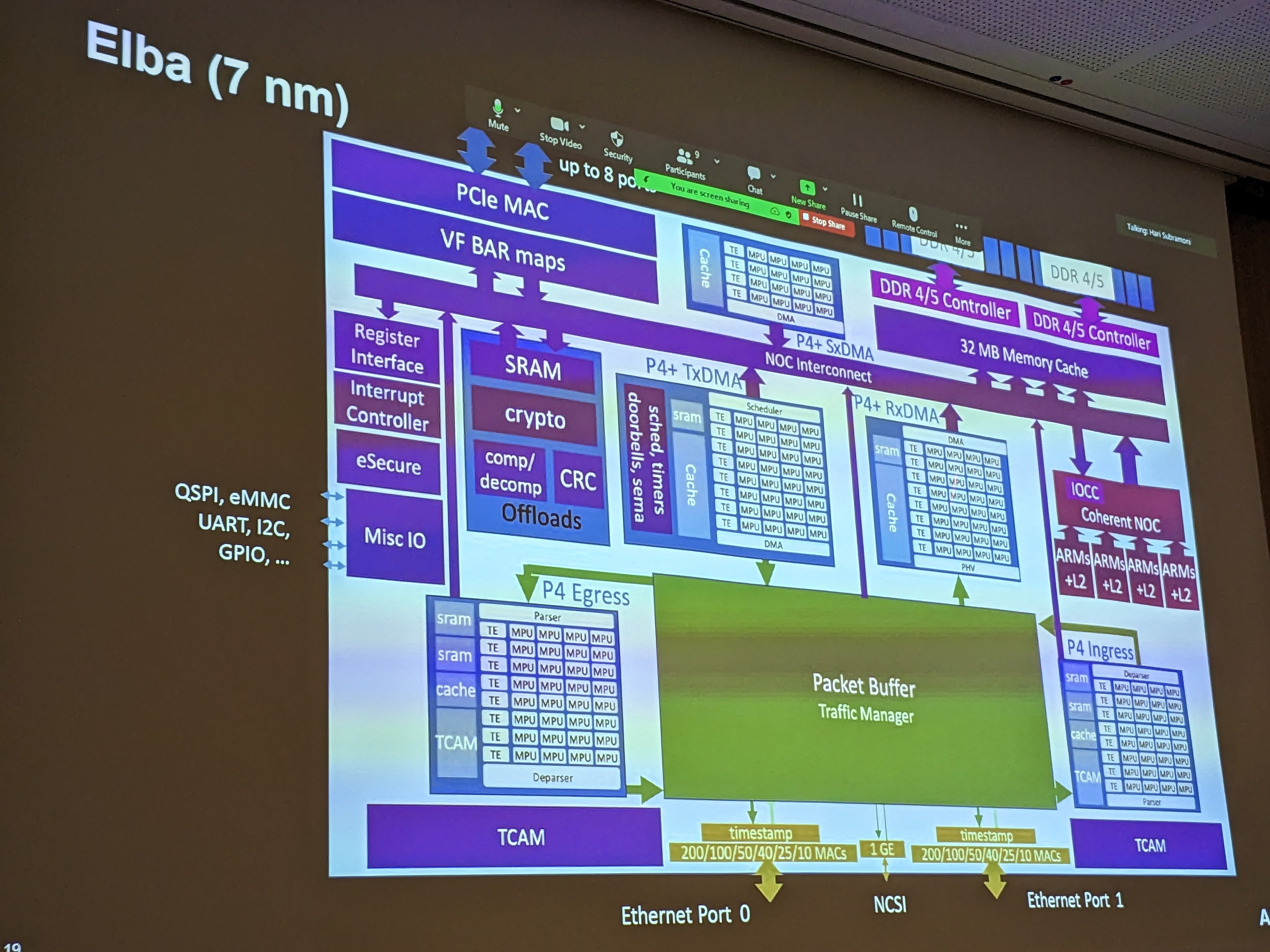
Speaker: Karthikeyan Vaidyanathan, Intel/Habana Session Chair: Aamir Shafi, The Ohio State University Title: Deep Learning Training using Gaudi2 Abstract: Exponential growth in deep learning across a wide range of application domains (image recognition, language models, recommendation systems and autonomous driving) has accelerated the need for training/inference within an hour or a few minutes. In this talk, I will highlight how Habana Gaudi2 processor significantly improves deep learning training and inference performance as compared to Gaudi1. More importantly, the talk will focus on how customers can scale Gaudi2 to several thousands of nodes with our in-built scale-up and scale-out RoCE v2 RDMA NICs. Finally, I will show the scale-up and scale-out Gaudi2 performance for collectives using HCCL and deep learning training performance of a few neural network models including vision and Large Language Models”. Speaker Bio: Karthikeyan Vaidyanathan (Karthik) is a Principal AI Engineer at Intel. His responsibilities include delivering best application performance in large-scale datacenters, defining and optimizing collective communication algorithms, coming up with novel framework-level optimizations and co-designing hardware/software for future scale-out systems. He has made significant contributions to MLPERF submissions, large-scale (up to ~10000 nodes) Top500, Green500 runs enabling Intel to achieve #1 ranking. He is an Intel Achievement Awardee, recipient of Intel Labs Gordy Award, and author of several top-tier conference papers and patents. He received his Ph.D. from The Ohio State University, USA. |
5:10 - 5:30 PM PDF YouTube |
Speaker: Kimon Karras, AMD Session Chair: Aamir Shafi, The Ohio State University Title: Heterogeneous, programmable silicon for high-performance network processing Abstract: Networking requirements nowadays push the envelope by concurrently demanding higher throughput, lower latency and increasing programmability to surmount challenges in HPC and the data center. These can be addressed only by harvesting software programmability together with heterogeneous hardware to deliver the most efficient solutions. This session will highlight how this is achieved by utilizing DPUs and SmartNICs that leverage the aforementioned technologies Speaker Bio: Dr.-Ing. Kimon Karras is a Computer Architect with AMD's Network Technologies & Solutions Group (NTSG). As a member of the NTSG's architecture group he's responsible for researching and specifying innovative architectures to tackle the challenges of the ever increasing throughput & latency demands. He has previously worked for Analog Devices and Xilinx where he participated in the design of high-performance networking & storage systems. |
5:30 - 6:00 PM PDF YouTube |
Moderator: Ron Brightwell, Sandia National Laboratory Title: Myths and Legends in High Performance Networking Summary: Following from a recent humorous and thought-provoking article analyzing factors and influences in high-performance computing, this panel will similarly explore the past, current, and future drivers impacting network hardware and software for extreme-scale systems in an attempt to separate truth from myth. Panelists will be presented with statements that they will need to evaluate and defend as fact or fiction. The analysis and discussion should provide insight into the priorities and potentially new directions for research and technology investments. Moderator Bio: Ron Brightwell leads the Scalable System Software Department in the Center for Computing Research at Sandia National Laboratories. After joining Sandia in 1995, he was a key contributor to the high-performance interconnect software and lightweight operating system for the world’s first terascale system, the Intel ASCI Red machine. He was also part of the team responsible for the high-performance interconnect and lightweight operating system for the Cray Red Storm machine, which was the prototype for Cray’s successful XT product line. The impact of his interconnect research is visible in technologies available today from HPE/Cray, Atos (Bull), Cornelis, and Nvidia/Mellanox. He has also contributed to the development of the MPI-2, MPI-3, and MPI-4 specifications. He has authored more than 115 peer-reviewed journal, conference, and workshop publications. He has served on the technical program and organizing committees for numerous high-performance and parallel computing conferences and is a Senior Member of the IEEE and the ACM. Panelists:
|
6:00 - 6:05 PM |
Closing Remarks Hari Subramoni, Aamir Shafi, and Dhabaleswar K (DK) Panda, The Ohio State University |