High Performance Computing with Virtualization
Overview
Description
In spite of such advantages, VM technologies have not yet been widely adopted in performance critical areas including HPC. This is mainly due to:
- Virtualization overhead: To ensure system integrity, the virtual machine monitor (VMM) has to trap and process privileged operations from the guest VMs. This overhead is especially visible for I/O virtualization, where the VMM or a privileged host OS has to intervene every I/O operation. This added overhead is not favored by HPC applications where communication performance may be critical. Moreover, memory consumption for VM-based environment is also a concern because a physical box is usually hosting several guest virtual machines.
- Management Efficiency: Though it is possible to utilize VMs as static computing environments and run applications in pre-configured systems, high performance computing cannot fully benefit from VM technologies unless there exists a management framework which helps to map VMs to physical machines, dynamically distribute VM OS images to physical machines, boot-up and shutdown VMs with low overhead in cluster environments.
This project, in collaboration with Dr. Jiuxing Liu and Dr. Bulent Abali from the IBM T. J. Waston Research Center, focused on low overhead I/O operation in Virtual Machine environment. Current objectives of this project are two folds:
- High Performance I/O in VM environment: we are exploring VMM-bypass I/O, which bypasses the virtual machine monitor (VMM) for time critical I/O operations by taking advantage of the OS-bypass features which are available with most of the high performance interconnects. The early results on this direction are presented in "High Performance VMM-bypass I/O in Virtual Machines". Our prototype XenIB, virtualizes InfiniBand in Xen VM environment. Currently the code is maintained through IBM Linux Technology Center and can be accessed using mercurial from: http://xenbits.xensource.com/ext/xen-smartio.hg. We are working on migration and checkpointing support for XenIB.
- Efficient VM-based Computing Platform: we are exploring the possibility to build a VM-based cluster computing platform for HPC applications. Design issues include: minimized and customized VMs, management and distribution of VM images, and efficient job scheduling in VM computing environment. Some of our early results show that applications using MVAPICH can run in VM environment with very little overhead compared to native, non-virtualized environment.
Results
Our testbed is an eight node InfiniBand cluster. Each node in the cluster is equipped with dual Intel Xeon 3.0GHz CPUs, 2 GB of memory and a Mellanox MT23108 PCI-X InfiniBand HCA. For VM-based environments, we use Xen 3.0. The Xen domain0 hosts RedHat AS4 with kernel 2.6.12 with 256MB memory. All user domains are running with a single virtual CPU and 896 MB memory, which allows two DomUs per physical machine. Each guest OS in DomUs uses the 2.6.12 kernel. The OS is derived from ttylinux, with minimum changes in order to host MPI applications. In the native environment, we use RedHat AS4 with SMP mode.
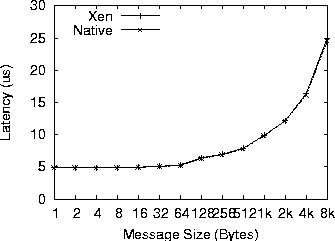
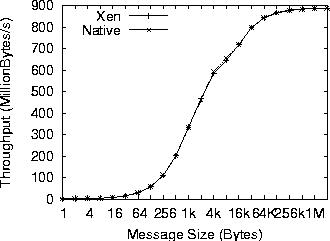
Above figures show the basic latency and bandwidth achieved in Xen and native environment. We observe that they are virtually the same with VMM-bypass I/O.
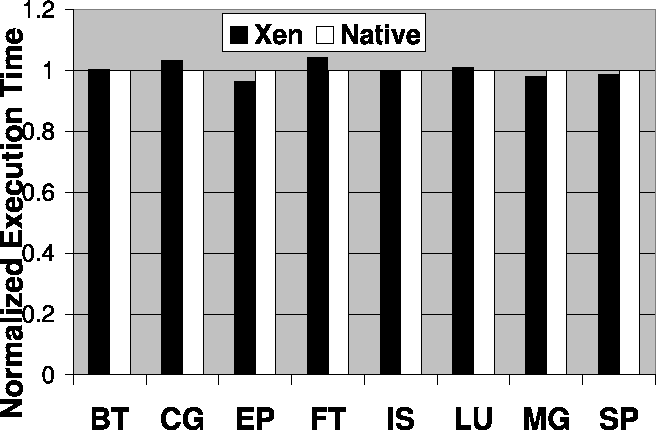
Above Figure shows the normalized execution time of NAS Parallel Benchmarks based on the native environment. We observed that Xen-based environment performs comparably with the native environment.
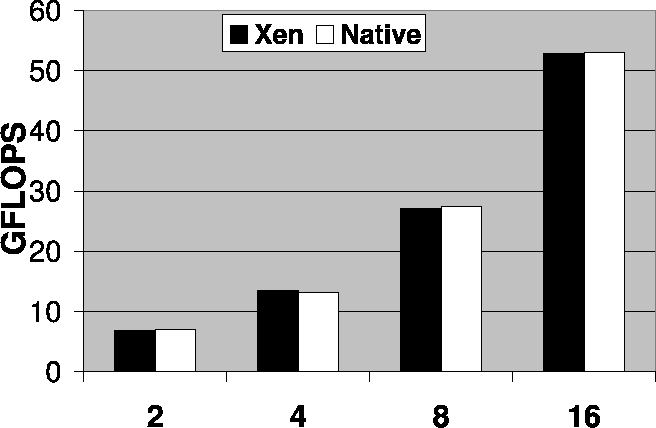
Above Figure shows the Gflops achieved in HPL on 2, 4, 8 and 16 processes. We observe very close performance here with native case outperforms at most 1%.
Journals (1) | |
|---|---|
| 1 | DK Panda, H. Subramoni, C. Chu, and M. Bayatpour, The MVAPICH project: Transforming Research into High-Performance MPI Library for HPC Community , Journal of Computational Science (JOCS), Special Issue on Translational Computer Science, Oct 2020. |
Technical Reports (1) | |
|---|---|
| 1 | W. Huang, J. Liu, B. Abali, and DK Panda, InfiniBand Support in Xen Virtual Machine Environment, OSU-CISRC-2/06--TR18 |